Python2-Scrapy学习(一)
以前写爬虫都是自己使用requests、bs4等库手工编写,最近想学学scrapy看看这个爬虫神器有多强大。
[
Install scrapy
使用pip安装scrapy即可。sudo pip install scrapy
scrapy的命令常用的有:startproject、shell、crawl等。
Scrapy runspider
使用scrapy runspider直接运行爬虫脚本。相对项目而言方便快捷。这里我直接使用官方文档的示例。
1 | import scrapy |
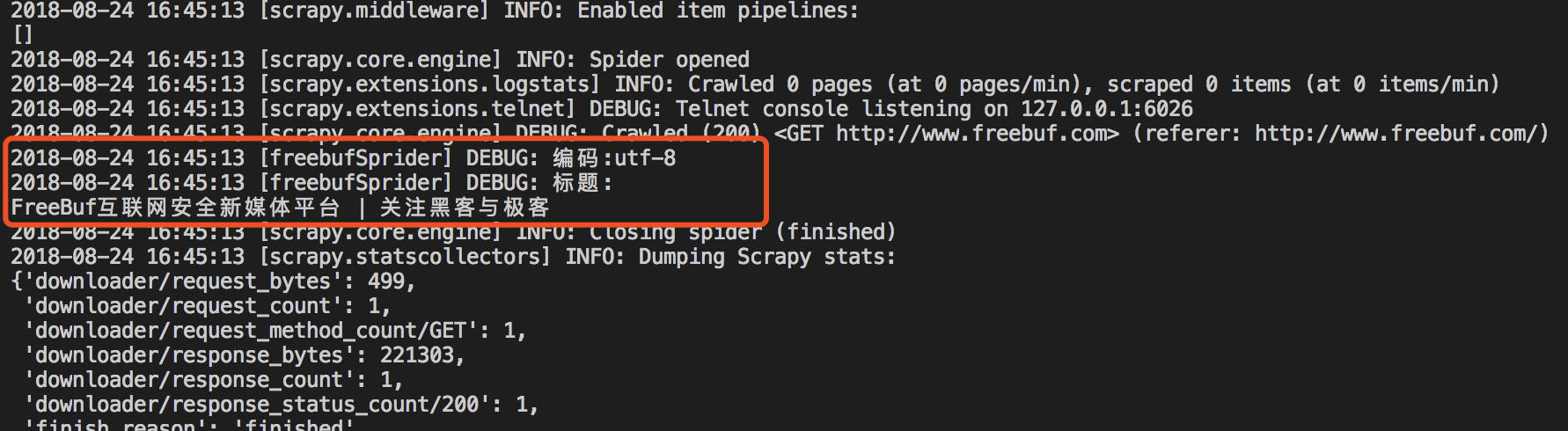
[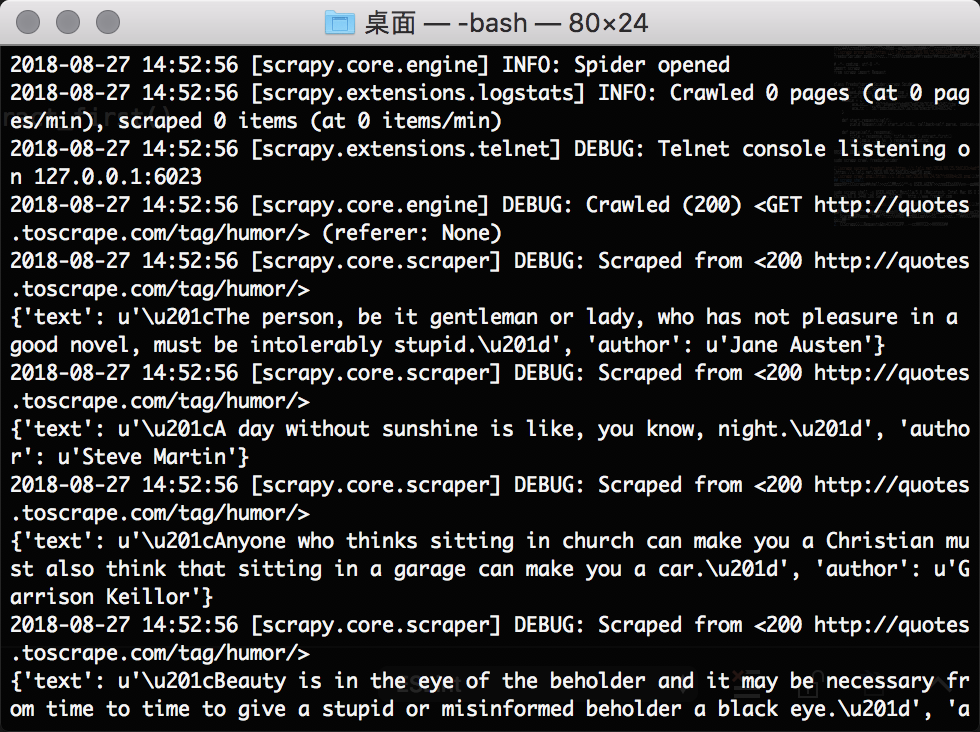 使用-o参数可以导出结果。 scrapy runsprider freebuf.py -o result.json [
使用-o参数可以导出结果。 scrapy runsprider freebuf.py -o result.json [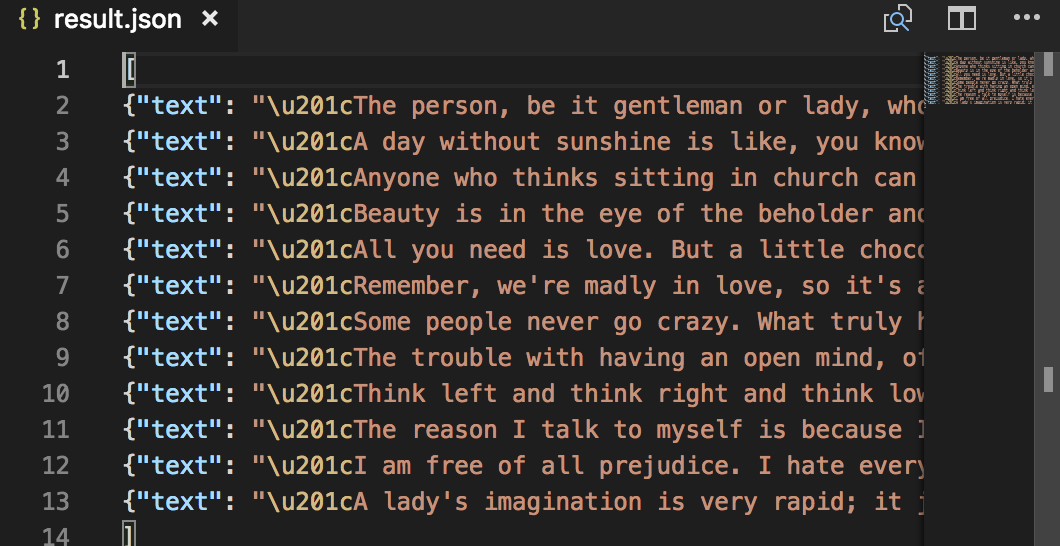
scrapy startproject
使用scrapy startproject创建爬虫项目。
Config setting
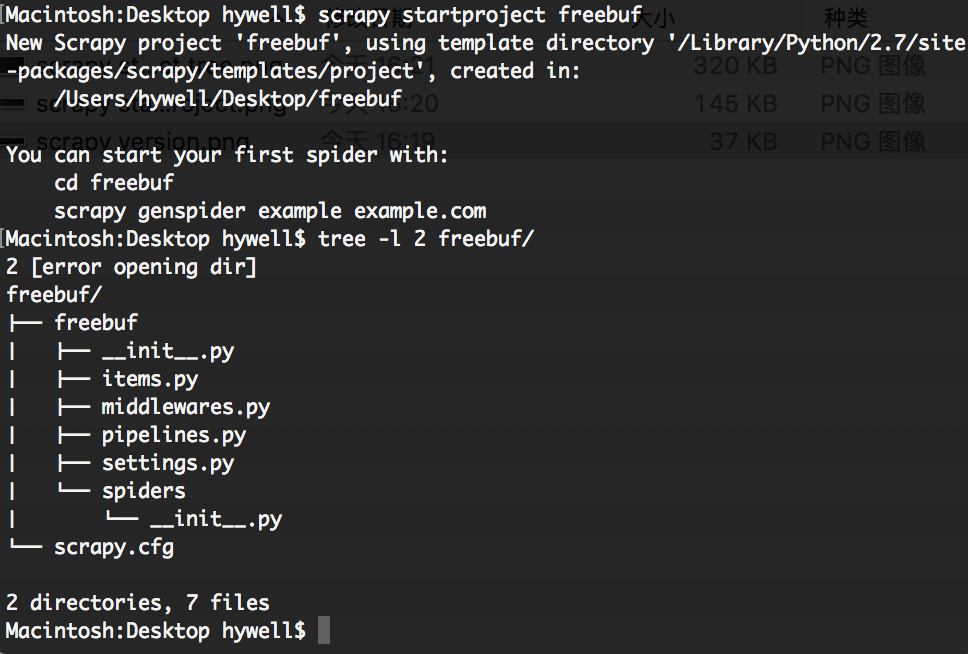
使用scrapy新建爬虫项目,这里我测试站点选择freebuf,建立一个爬虫项目。scrapy startproject freebuf
进入freebuf目录,创建基础爬虫。scrapy genspider freebufSprider "freebuf.com"
之后目录结构如下图:
[
进入freebuf目录下,查看settings.py配置文件。下面列出几个需要修改的配置。
1 | ROBOTSTXT_OBEY = False(不遵循Robots.txt规则) |
scrapy crawl
一开始对freebuf进行爬虫的时候,发现响应包返回不正确。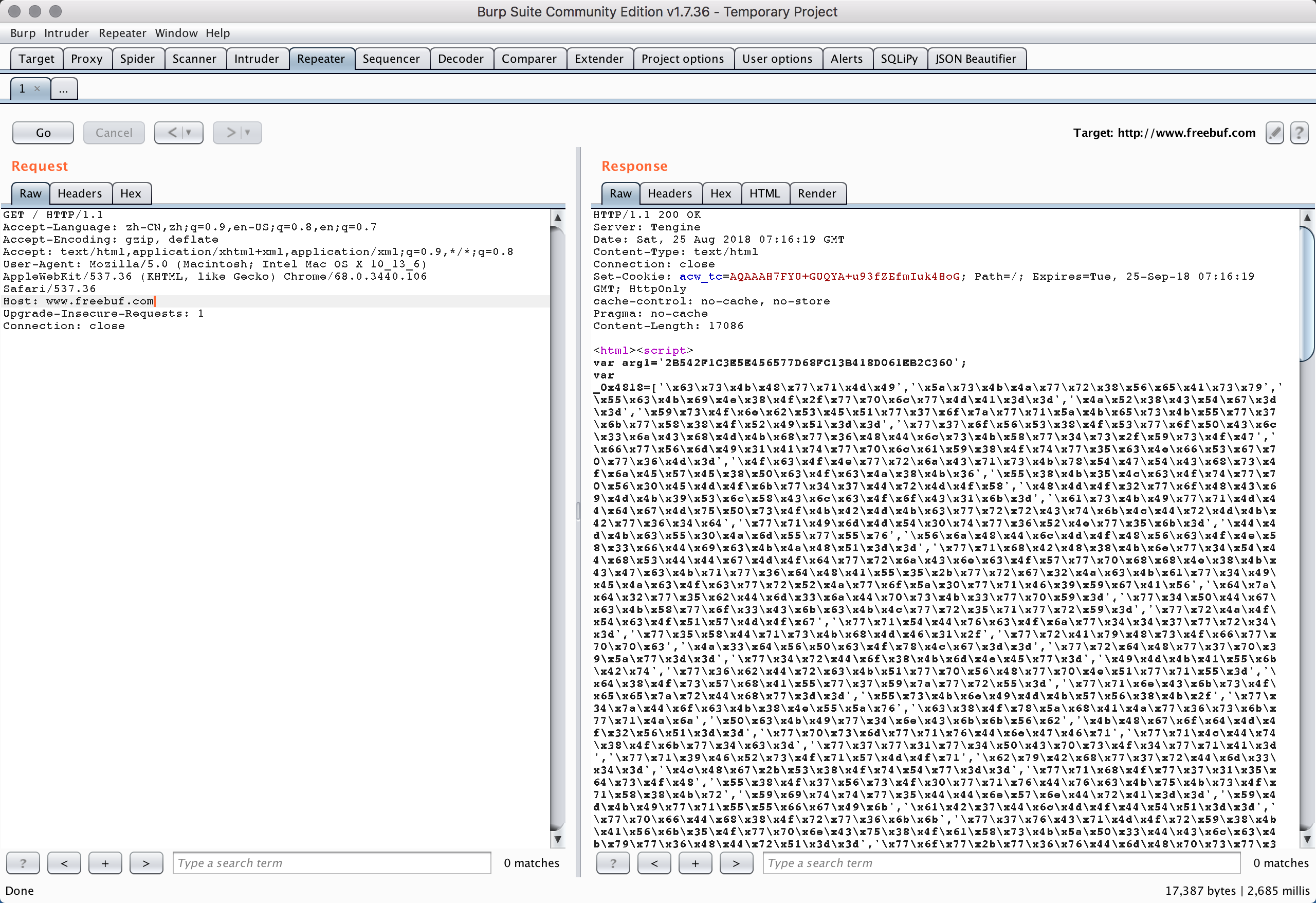
初步猜测freebuf站点有反爬虫的策略(猜测主要有四点:User-Agent、Cookie、Referer、请求间隔)。为了方便查看请求包,对请求设置HTTP代理。
修改settings.py文件中的DOWNOLOAD_MIDDLEAWARES
1 | DOWNLOADER_MIDDLEWARES = { |
如上配置,请求包会通过代理发送到本地8080端口。这里,我使用BurpSuite进行代理拦截。
[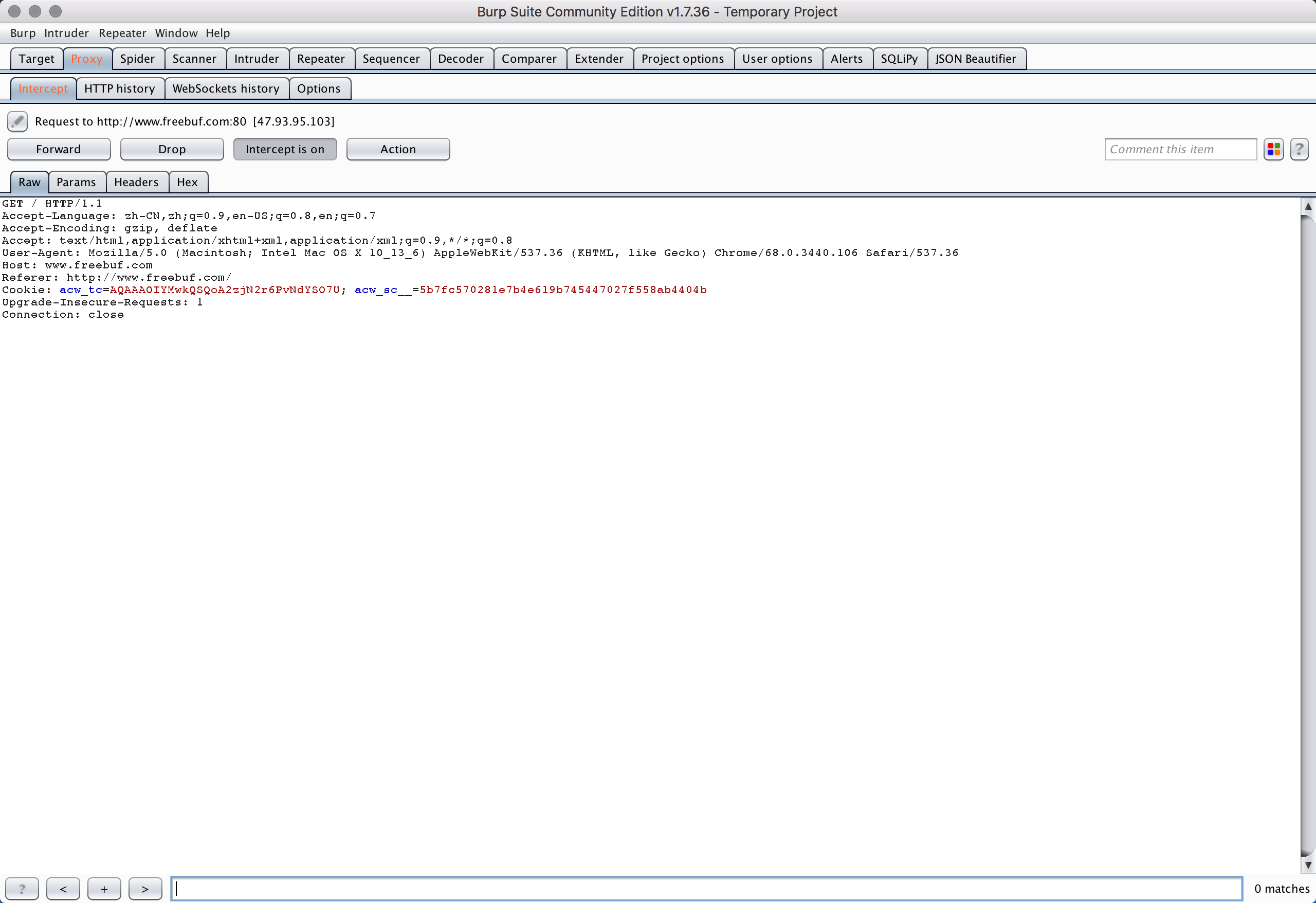
freebufSprider.py文件进行编写,设置cookie。freebuf的cookie最主要的有两个:acw_sc、acw_tc。
1 | # -*- coding: utf-8 -*- |
在项目目录下执行sudo scrapy crawl freebufSprider
[
scrapy shell
也可以使用scrapy的shell进行测试,通过-s USER_AGENT进行请求头设置(不知道为什么使用shell命令,不带cookie也会得到正确的回显)。sudo scrapy shell -s USER_AGENT='Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' 'http://www.freebuf.com
[
总结
针对不同站点写爬虫的时候,首先需要对站点有所了解:robots.txt、反爬虫机制等。
- Scarpy爬虫项目相对自己编写的爬虫,整体感强,作为一整个项目来进行编写。以前的那种写法,经常一个脚本就要包含一大堆东西,到最后整体很乱,不利于后期代码维护;
- 用Scrapy或者Requests&bs4都需要对目标站点需要有所了解;
- 单个脚本的scrapy提供了导出等API接口,相对自己写的更方便。