Python2-Scrapy学习(二)
继续学习scrapy,这次学习如何进行数据爬取。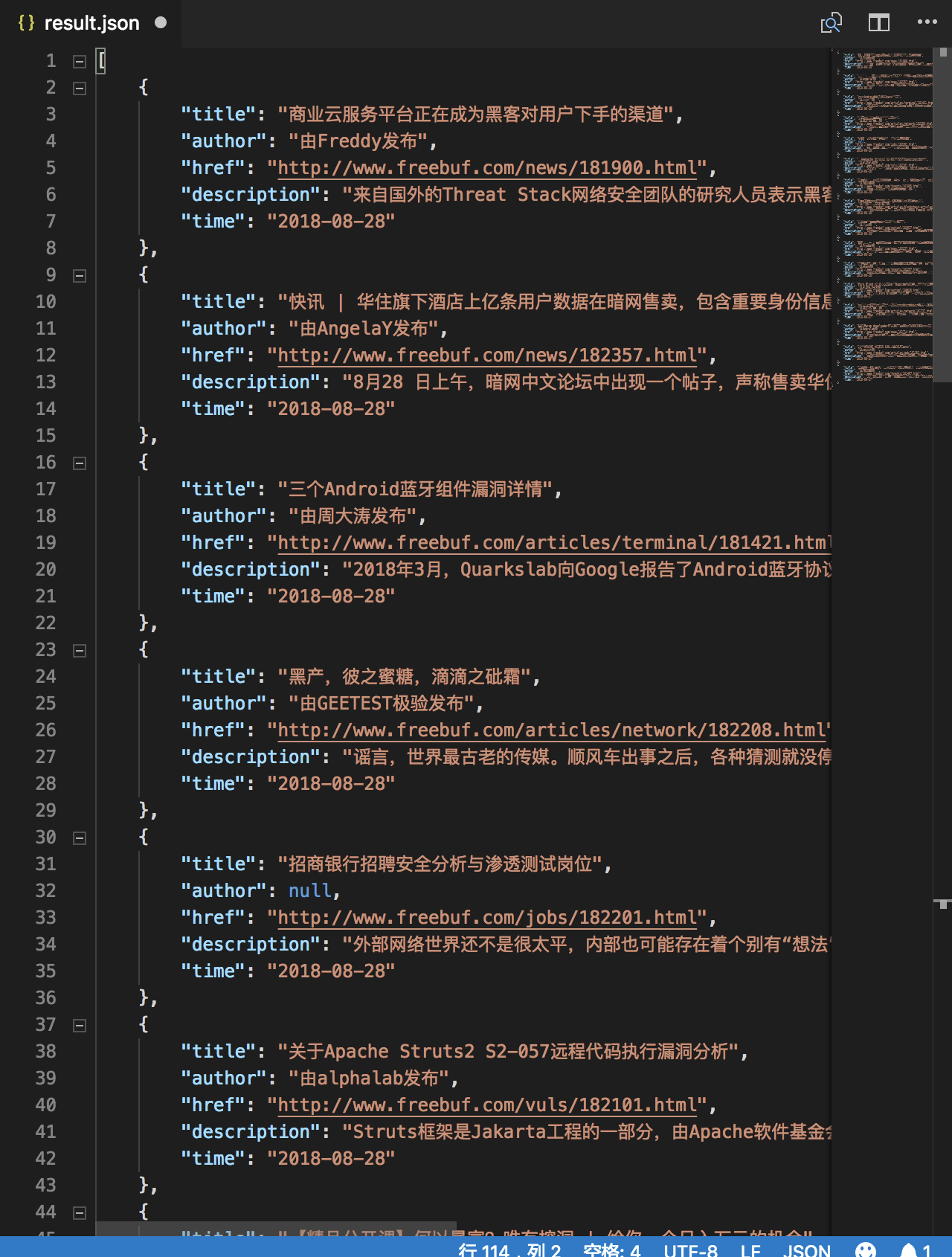
在Python2-Scrapy学习(一)大致了解了scrapy的基础使用方式,接下来开始使用scrapy结合xpath爬取所需的信息。
freebuf资讯爬取
假定需要爬取的是freebuf最新的资讯,通过Chrome的Elements可以看到资讯的信息在class=news_inner news-list的div中。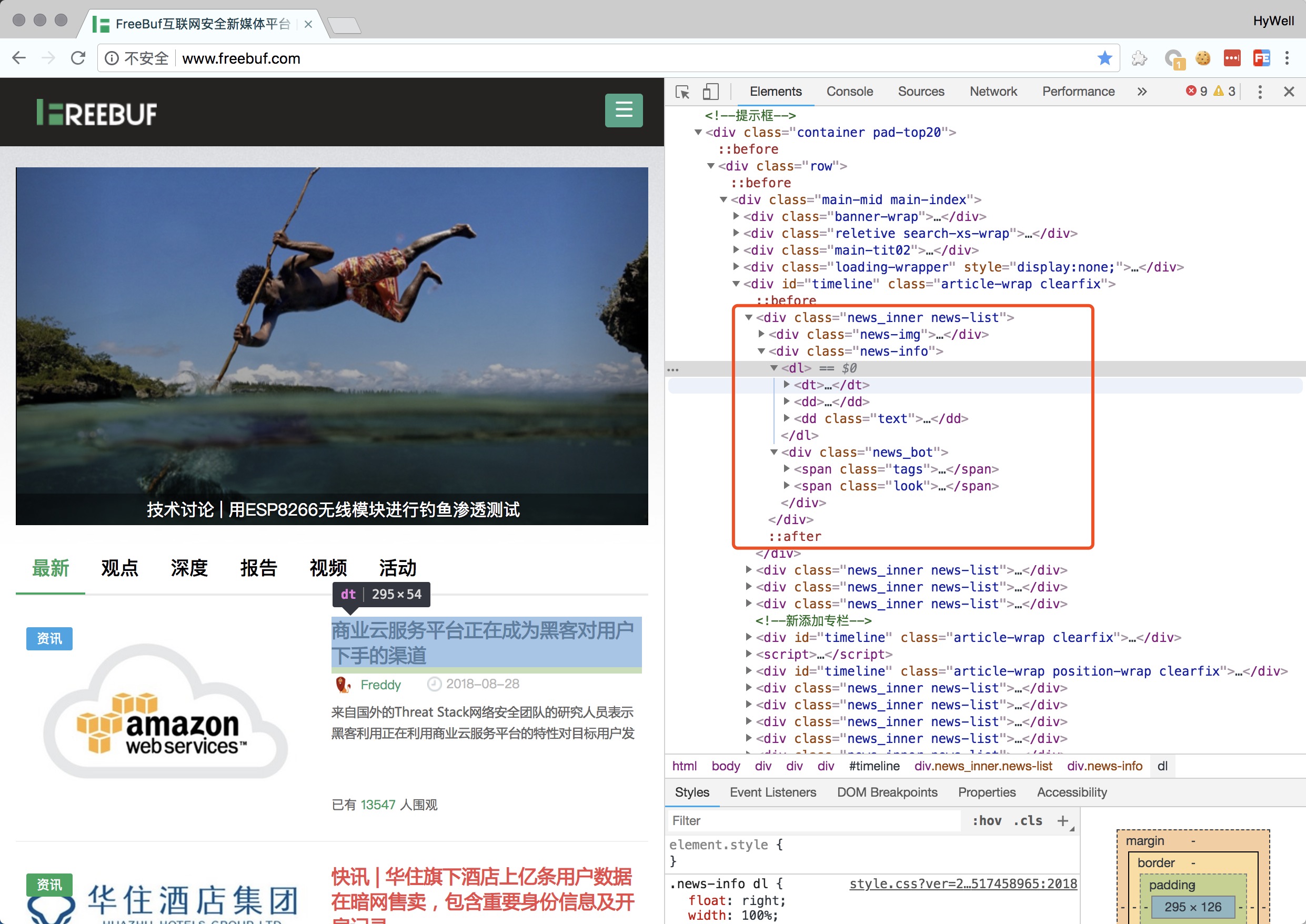
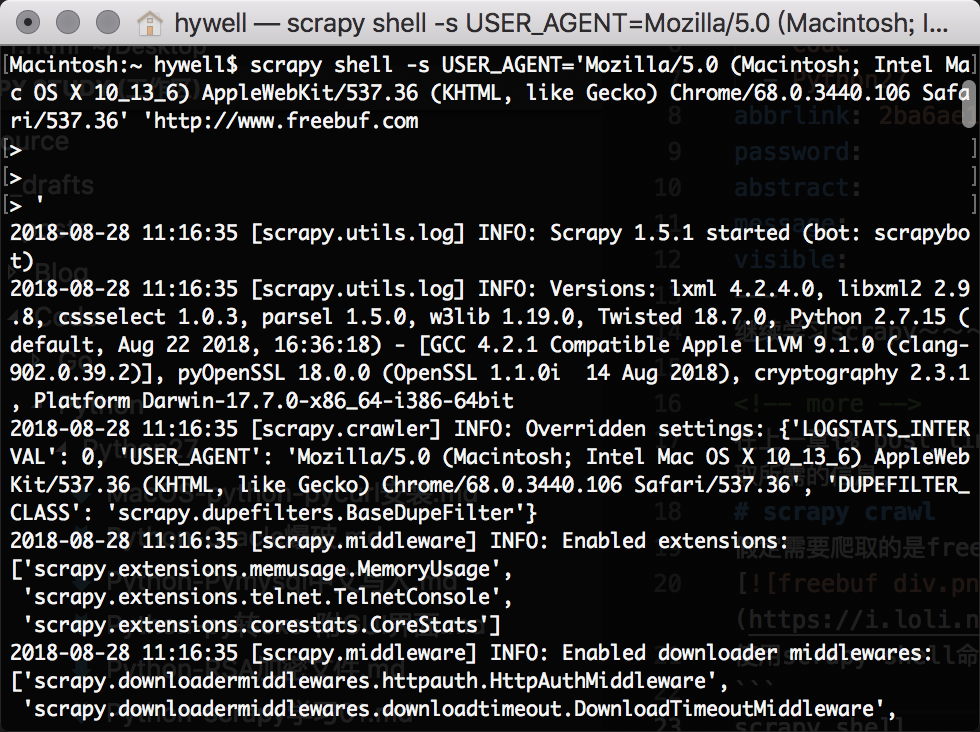
使用scrapy shell命令进行调试。
1 | scrapy shell -s USER_AGENT='Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' 'http://www.freebuf.com |
使用xpath选择器来筛选需要的数据。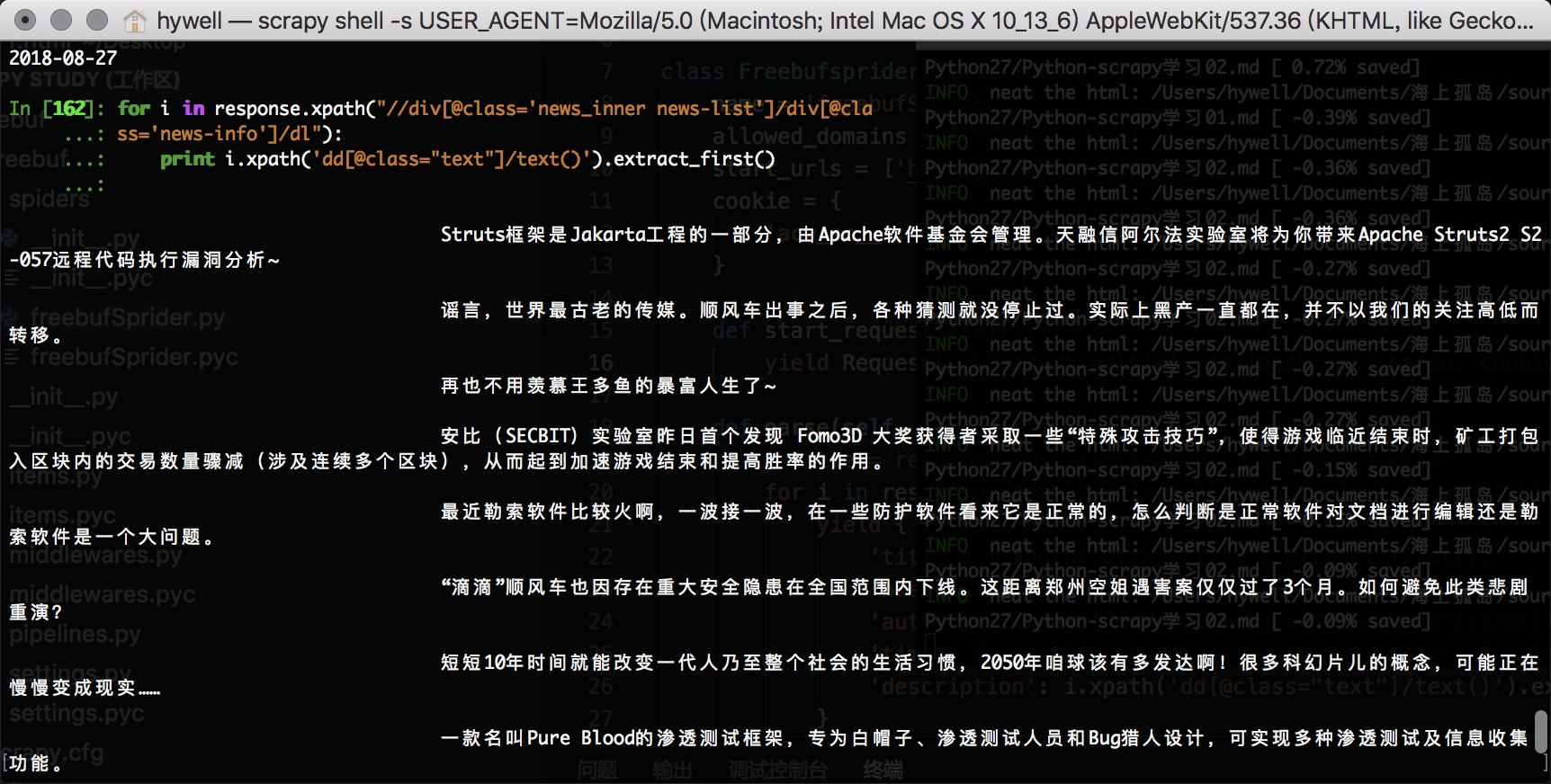
最后使用scrapy crawl freebufSprider -o result.json可将结果保存至result.json中。
总结
- 爬虫的步骤:访问站点、解析数据、获取数据。
- scrapy支出css、xpath,大家看哪个顺手就用那个好了。
完整代码
完整代码已经上传到GitHub。如果有兴趣,不妨移步到Github上一观!**Code**。