Python2-并发爬虫
现在数据就是王道,而爬虫就是获取数据的快速途径之一!
准备
看标题,咱们就应该知道需要用到Python27。本文通过Python 结合 requests库进行爬取操作,BeautifulSoup4使用lxml进行解析操作,gevent进行并发操作。
Python27
选择对应的操作系统的Python27进行下载。下载完成进行安装,之后配置环境变量即可。环境变量需要配置两处,一处是Python27的安装目录,一处是Python27安装目录下的Scripts目录。
环境变量配置
右键【我的电脑】→【属性】,点击【高级系统设置】中的【高级】选项卡中【环境变量】,在【系统变量】窗口中找到【Path】变量。点击【编辑】,加入对应的环境变量(例如D:\Code\Python27、D:\Code\Python27\Scripts)。如果是Win10系统,新建两条即可。如果是Win10等系统,点击编辑之后在后面加入;D:\Code\Python27;D:\Code\Python27\Scripts即可。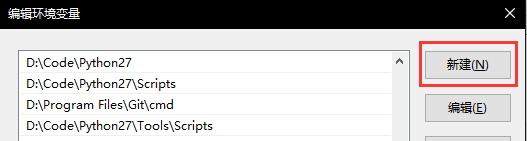
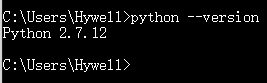
1 | python --version |
1 | pip --version |

Requests
使用pip快捷安装requests。
1 | pip install requests |
BeautifulSoup
使用pip快捷安装BeautifulSoup4。
1 | pip install beautifulsoup4 |
lxml
使用pip快捷安装lxml。
1 | pip install lxml |
Gevent
使用pip快捷安装gevent。
1 | pip install gevent |
爬取流程
在准备阶段,咱们已经将“斧柄”、“斧刃”准备好了,到时候把两个组装起来,选一棵树,进行“伐木”工作。
爬取流程分为:获得url、访问url、解析页面、获取页面url。
入口url
由于本文只爬取站点中存在的url,并不取特殊数据。因此,入口url可以自定义输入。
1 | entry_url = raw_input('Place enter the entry url:') |
请求页面
请求页面操作通过使用requests库来完成。如果对requests库感兴趣,可以参考官方文档。
想要使用requests库,需要先导入requests库。这步操作就是将斧柄(Pythnon27)、斧刃(requests)组装起来。
1 | import requests |
接下来就需要使用requests库的get方法。
1 | r = requests.get(entry_url) |
解析页面
通过上面的操作,咱们已经获取了页面的信息。然后就是BeautifulSoup4发挥的时候了。如果对BeautifulSoup4库感兴趣,可以参考官方文档
1 | from bs4 import BeautifulSoup |
本文爬虫只需要获取站点url即可,不需要获取站点特殊数据。因此,获取a标签的href方法的值即可。
1 | soup = BeautifulSoup(r.text, 'lxml') |
异步爬取
异步爬取可以让程序执行更快,时间既是生命。如果对gevent库感兴趣,可以参考官方文档。
队列
队列(Queue)适用于多线程编程,让数据安全地在生产者与消费者之间进行信息传递。
让url放在队列数据结构中,可以让队列自动帮我们销毁已经被调用的url。
1 | from gevent.queue import Queue |
异步工作
将工作流程制作成函数,调用gevent.spawn形成工作队列。当适当的时候执行。
1 | import gevent |
总结
在编写并发爬虫的时候,遇到了几个问题,在此记录一下。
- url请求是http还是https,如果是https的话,需要将requests的verify设置为False;
- 并发的时候如何判断任务是否已经结束?我是通过判断队列为空并且无待工作的任务,不知道这种判断方式是否可取。有没有好心人告诉我有什么优雅的方式么;
- 如果对并发量不进行设置的话,有可能导致内存飙高。我通过对线程列表进行设置,当线程列表到100时就运行一次。同求优雅的方式;
- href方法里面存在两种情况:包含域名(href=”http://xxx.com/index.html"),不包含域名(href="/index.html");
- 用户输入与href方法内情况不同。例如用户输入https://www.iassas.com,页面href标签是https://iassas.com(或者两者反一下)。现在就按照用户输入为准;
- 子域名链接爬取,现在判断逻辑不爬取子域名;
- href方法中的url有可能会带有#(跳转对应页面位置),模拟浏览器是将#后面所有字符不当成url考虑;
- url会被url编码,调用urllib.unquote来解码。
完整代码
完整代码已经上传到我的GiHub。如果有兴趣,不妨移步到Github上一观!**Code**。由于Web环境千奇百怪,程序出错在所难免。请体谅!