AWIScan编写之路
红队评估、渗透测试等安全工作最为重要的就是信息收集,信息收集工作需要对目标多方面、多维度进行收集、梳理。相信大家也用过许多信息收集的工具,例如:nmap、msscan、subdomainBrute、whatweb、dirscan、dirsearch、wydomain等等。当对一个目标群体(多ip段 or 多域名)进行信息收集时,往往需要不断在各个工具之间来回切换。通过寻找发现了一款工具:FuzzScaner,该工具整合了子域名、端口、指纹、c段等信息收集。但FuzzScaner存在几点问题:1.长期不维护&更新,上次提交为2019.04;2.使用python2,python2马上不被官方支持;3.只做了简单整合,多工具调度之间容易出问题。因此,自己动手造了一个轮子:AWIScan——All Web Info Scan。
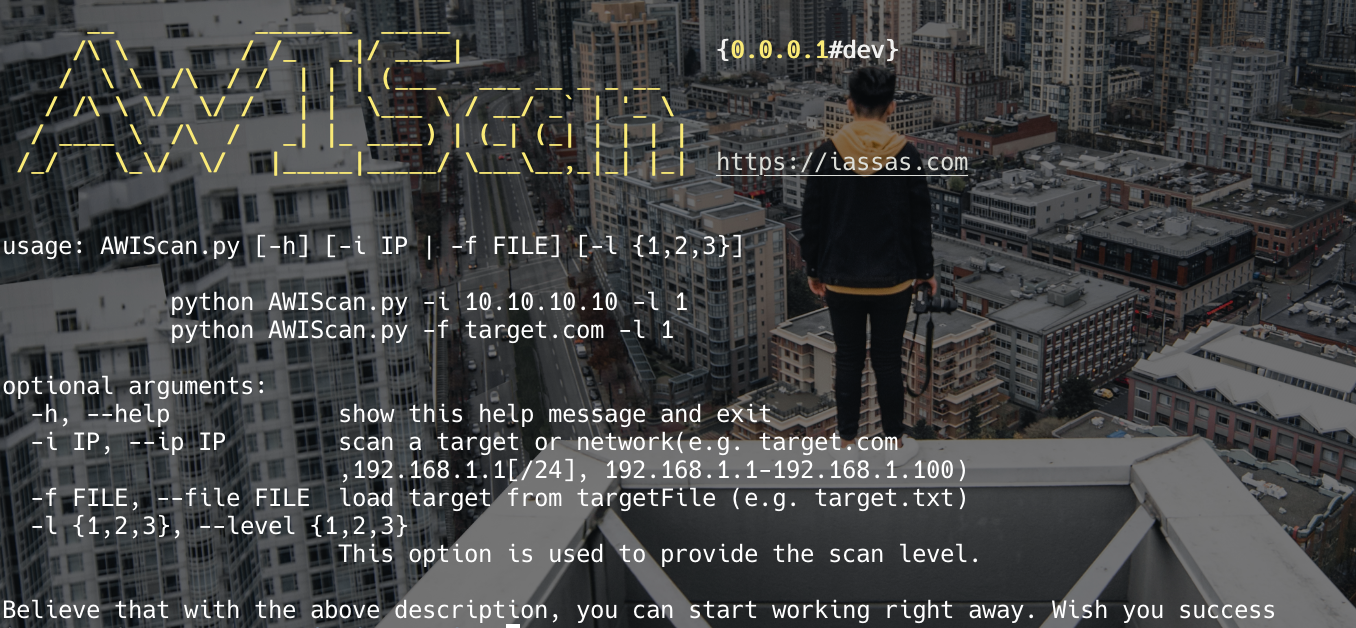
功能构思
根据上面所述,新开发的工具需要具备如下特性:
- 尽可能快的完成任务
- 尽可能多的收集信息
- 尽可能少的参数输入
- 最好支持插件或模块拓展
根据上述特性,采用了
- Python3 asyncio协程
- 支持端口扫描(调用nmap)、子域名爆破、目录爆破
- 总共三个参数,可直接使用单个参数即可执行 任务,其中level参数可不输入,默认为1
- 需要修改的配置信息都在setting.py文件中
框架流程
这里借鉴了许多项目:SQLMap、PocSuite3、subdomainBrute、Dirscmap、Dirsearch、FuzzScaner等等。最终结构如下
1 | . |
流程为:参数解析——配置注册——任务分配——开始工作——输出结果。
使用说明
初始目标支持以下几种格式:
- 192.168.1.1
- 192.168.1.1/24
- 192.168.1.1-192.168.1.100
- 192.168.1.1-254
- domain.com
- [http/https]://domain.com
现版本根据不同的输入目标会执行相应的功能:
纯ip地址执行端口扫描,e x 192.168.1.1…域名会执行子域名爆破,e x domain.comurl会执行目录扫描,e x http://domain.com or https://domain.com
所有初始目标都会执行端口扫描,如果没有协议会再执行子域名爆破、如果还有协议会再加上目录扫描。
该版本只在OSX、python3.7下测试过,别的系统版本可以自己试试(估计问题不大)。
Windows(10)、linux(Debian)、MacOS(10.15) && python3.7皆测试通过。
由于端口扫描是调用nmap的,本地机器需要安装nmap,并且执行脚本需要有对应权限,可在lib/core/setting.py中配置SUDO_PASSWORD。具体端口扫描速度并未进行测试。
由于端口扫描是调用nmap的,本地机器需要安装nmap,并且执行脚本需要有对应权限,可在lib/core/setting.py中配置SUDO_PASSWORD。具体端口扫描速度并未进行测试。
子域名爆破需要指定对应DNS服务器,整体速度子域名爆破一千三百多个,最快一次是三十多秒(估计有dns缓存的原因)。清理缓存,再次测试七分钟左右(协程数50)。
目录扫描由于设计到网络、防护等关系,未进行测试。
问题难点
在编写的时候遇到种种问题和难点:
- 协程库的资料相对较少
- 许多库在调用中会出现千奇百怪的问题
- 慢速生产、快速消费模型,如何保持消费者数不减少
针对第三个模型做一下记录:下面代码有可能导致最后只有一个协程在工作,但任务队列中还具备无数任务
1 | import asyncio |
后面在主协程中同归队列进行阻塞,子协程阻塞至任务获取,即可解决该问题。即所有子协程都不断运行,直至取不到任务时阻塞。
1 | import asyncio |
下面再记录一下小问题
通过asyncio.queue设置队列最好在对应协程函数中建立:一开始将工作队列设置成全局,然后在各个文件进行加载,该方式会导致异常,大概含义是一个loop只能使用同一个队列。
由于协程概念,所以最好只使用一个loop:在进行dns服务器测试的时候通过get_event_loop建立了新的loop之后(完成任务之后loop.close),在后续再次通过get_event_loop是无法成功新建协程的:RuntimeError: Event loop is closed。可通过set_even_loop解决,但不建议。
异步DNS库还不够完善,在aiodns、async_dns、aiodnsresolver中来来回回切换,最后选择了aiodns。
- aiodns未看到timeout参数,所以子域名爆破有可能超时导致速度不稳定
- async_dns在DNS服务器测试完成之后,再此调用返回的结果为空,估计是由于不同loop的原因导致?
- aiodnsresolver在进行dns服务器配置感觉不太好用,所以弃用。
后续计划更新
- 目录爆破支持随机User-Agent
- 目录爆破支持代理
- 整合目标,将ip、domain这些统一整合
- 支持多进程扫描
- 支持自定义插件扫描
- 强化扫描能力
- 。。。
总结
- 感谢GitHub上这么多开源的工具
- 写代码好难~~~
- 在遇到问题查看官方文档如果无法解决,可以直接看对应源码
- AWIScan项目应该有很多面条式代码,后续看看能不能逐渐优化
- 对变量进行命令真的太难了,所以很多地方用了同样的变量名。全局变量设置成全大写,局部变量是全小写,不同参数传递参数前面变量名相同(尽量)